Introduction
The Text to Speech Generator is a powerful tool that leverages OpenAI's API to create audio files from textual descriptions. This feature allows users to enter a prompt, which is then processed to generate a corresponding audio file. The generated audio file can be previewed and saved for future use. This section provides an in-depth look at how the Text to Speech Generator works.
Code Breakdown
The TextToSpeechScreen class manages the text-to-speech functionality within the application. It allows users to input text, convert it into speech, and save the resulting audio file. The key functions are designed to handle user input, generate speech, and manage errors during the process.
The main components of this class include:
- generate_speech: Converts user input text into speech using the gTTS library and saves the audio file.
- go_back: Provides navigation back to the home screen.
Code Samples
generate_speech Function Sample
The generate_speech function is responsible for converting the text entered by the user into speech. It uses the gTTS library to process the text and saves the resulting audio file in the "speech" directory with a timestamped filename. Error handling ensures that users are notified if something goes wrong during the process.
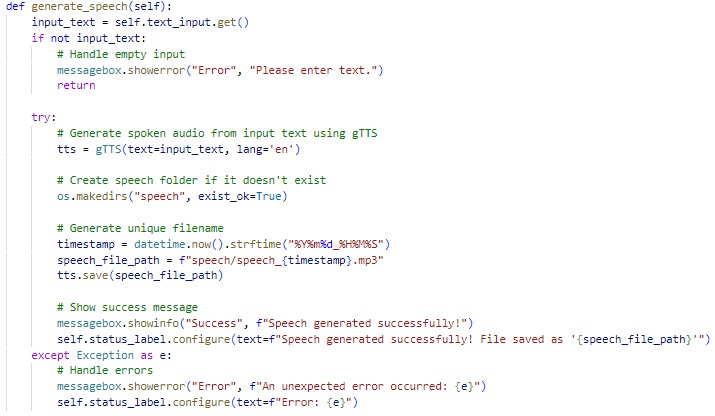
The function dynamically checks and creates the "speech" directory if it does not exist, ensuring that the application can save multiple audio files without running into directory-related issues. This feature maintains smooth functionality even when handling numerous speech generation tasks.
Solution Visualization
Below is an example of the printed output illustrating how the solution is presented:

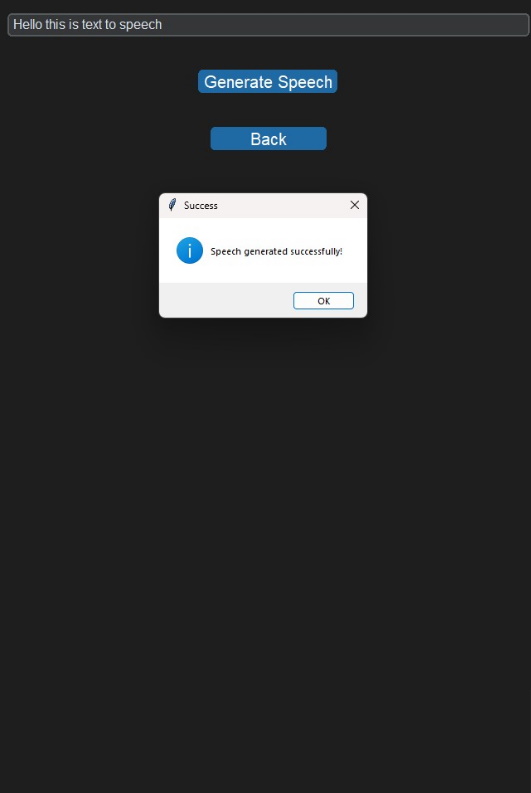
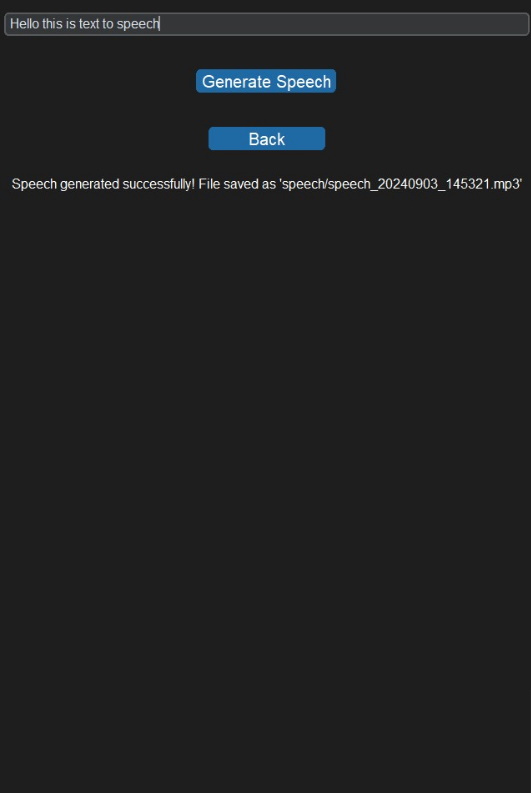
Conclusion
The text-to-speech functionality provides users with a straightforward way to convert their text into spoken words. The process is efficient, with clear error handling to ensure a smooth user experience. This feature, combined with the image generation tool, makes the application a versatile AI-powered utility.